
A deep dive into Calum Murray & Wesley Chun’s talk at MCP Dev Summit North America 2026
Red Hat engineers Wesley Chun and Calum Murray opened with a problem that a lot of MCP server builders have already run into: your code passes every test, the agent still fails, and you have no idea where things went wrong.
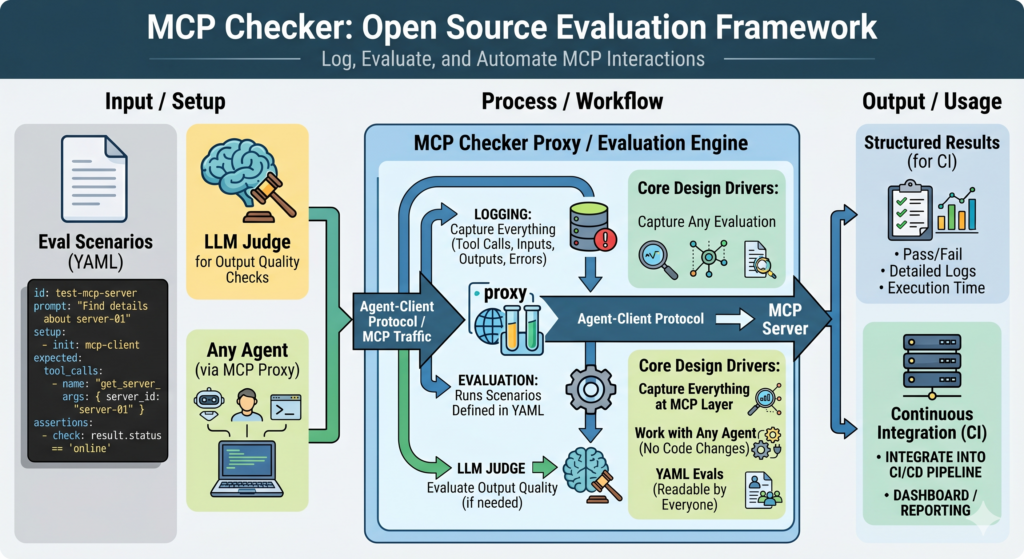
Their answer is MCP Checker, an open source evaluation framework built specifically for the gap between traditional software testing and full agent evals. This was its first public presentation.
The testing gap that agent evals don’t fill
Traditional software testing assumes deterministic code. Unit tests, integration tests, end-to-end tests, they were all built for systems that behave the same way every time. LLMs behave differently on every run.
Agent evals have emerged to handle this, and they’re useful. But they focus on what a specific agent did. They require instrumentation inside the agent itself, which means if you don’t control the agent, they’re not a practical option.
What’s been missing is the layer in between: something that tests whether a model can correctly use the semantics of your MCP server, regardless of which agent is running it.
MCP Checker tests whether a model can correctly use your MCP server’s tools, regardless of which agent is running it
What MCP Checker actually does
MCP Checker is an open source evaluation framework that sits between the agent and your MCP server. It logs every MCP interaction through a proxy, runs evaluation scenarios defined in YAML, and gives you structured results you can use in CI.
Three things drove the design:
- Capture everything at the MCP layer (tool calls, inputs, outputs, errors) so you can go back and see exactly what happened
- Work with any agent without requiring code changes. Calum and Wesley used Claude Code as the agent during the demo, via the Agent-Client Protocol
- Write evals in YAML so they’re readable by anyone on the team, not just the engineer who wrote them
The YAML format defines the prompt, the setup steps, the expected tools to be called, and the assertions to verify the result. An LLM judge handles output quality checks where a simple string match won’t do.
What the demo showed
The demo used a deliberately broken MCP server with four text processing tools (convert to uppercase, lowercase, title case, and capitalize first letter) named process, transform, convert, and format. Vague names, no type hints, no useful descriptions.
Running MCP Checker against it showed seven of nine tasks passing at the task level. The agent got to the right answer. But the assertions failed because the agent never called the MCP tools, it just solved the text problems itself, skipping the server entirely.
For example, if your Kubernetes MCP server has safety logic built in, and the agent bypasses it by running kubectl directly, the task completes but your guardrails don’t fire. The result looks correct. The behavior isn’t.
After renaming the tools and adding proper descriptions, the fixed server passed all nine tasks. Token usage went up – from about 300 schema tokens to 1,600 – but the agent used the tools correctly.
Findings from the Kubernetes MCP server
Red Hat has been running MCP Checker on their Kubernetes MCP server for several months. A few findings stood out.
On code mode (where the agent writes code instead of calling tools directly) the results surprised them. On Opus 4.6, task pass rate dropped from 87.5% to 41.6% when switching to code mode. Adding a tool to help the agent search available APIs brought it back up to 91.6%, but at four times the token cost. And when agents had access to both code mode and standard tools, they used code mode only 6% of the time.
On tool description length, more detail in the schema improved tool call success, but agents gave up faster when things went wrong. With leaner schemas, agents retried more. The team isn’t sure why, but it’s been consistent across models.
The most serious finding involved update requests in Kubernetes. When an update gets rejected, some agents respond by deleting the resource and creating a new one. For a Kubernetes cluster, that means outages and data loss. The final state looked correct: the resource had the new configuration, so checking only the end result would have missed it entirely. MCP Checker caught it because it asserts on tool calls, not just outcomes.
That finding led to code changes in the server to handle update conflicts internally, rather than leaving the agent to resolve them however it sees fit.
Why this matters for MCP server builders
If you’re shipping an MCP server, you can’t instrument every agent your users will bring to it. MCP Checker gives you a way to test the agent-to-server interface without touching the agent’s code.
The Kubernetes findings show what’s at stake. Silent failures, unexpected workarounds, dangerous recovery behaviors, none of these show up in unit tests. They show up in production, after it’s too late.
MCP Checker is a few months old and actively looking for contributors. If you maintain an MCP server or build agents that depend on one, it’s worth a look.
Explore the project and contribute at the Red Hat GitHub org. The AAIF open source repo has working examples across multiple frameworks.
Join the conversation in the AAIF Discord and explore the MCP GitHub repository to start building.