

Agentic AI is redefining the infrastructure standards that we just got used to.
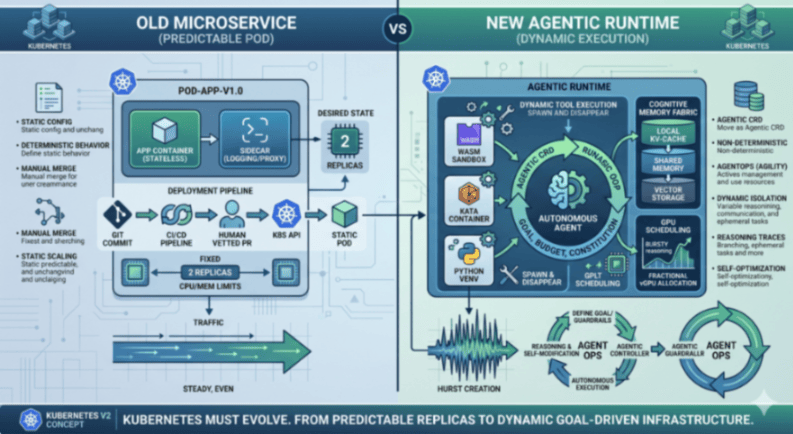
For the better part of a decade, the “Microservice” has been the undisputed unit of value in software engineering. We spent years perfecting the art of the stateless, predictable container, wrapping it in layers of GitOps and CI/CD pipelines to ensure that what we deployed yesterday is exactly what runs tomorrow. But now we are witnessing the rise of a new occupant in our clusters: the Autonomous Agent.
What we can see is that we have the right engine, but we are using the wrong blueprints. Kubernetes, with its immense extensibility and hardware abstraction, remains the only platform capable of hosting the agentic future. However, the design patterns we’ve inherited, the “best practices” of 2022, are actively hindering the growth of autonomous, agentic systems.
To truly serve an agentic ecosystem, we must stop treating agents like static web apps and start treating them like the dynamic, cognitive processes they are.
The Problem with Predictability
The core of the conflict lies in the nature of the workload. Traditional Kubernetes patterns thrive on “Desired State.” A human defines exactly how many replicas should run, what their memory limits are, and how they should communicate. Agents, by contrast, are inherently non-deterministic. They don’t just respond to traffic; they generate logic, they spawn sub-tasks, and they mutate their own requirements based on the complexity of the goal at hand.
Look at a tool like goose. When Goose is tasked with a migration, it doesn’t just sit there; it autonomously decides which tools to invoke and which environments to spin up. If Goose decides it needs a temporary Python environment to process a dataset, it will do. Our current GitOps flow, requiring a human-vetted PR, is a brick wall in such cases. The infrastructure needs to be as agile as the agent it hosts.
Our current infrastructure treats a “crash” as a failure to be mitigated by a restart. But in an agentic world, an agent might purposely spin up a temporary environment to test a hypothesis, execute a generated script, and then tear it all down. Agents cause intentional instability or ephemeral execution that looks like a failure to a traditional orchestrator. So our current reliance on human-vetted GitOps, where every infrastructure change requires a Pull Request and a manual merge, has become the ultimate bottleneck.
Building the Four Pillars of the Agentic Runtime
To bridge this gap, the infrastructure must evolve to provide four native capabilities that were once considered “nice-to-haves” but are now fundamental requirements for safety and performance.
First, we must address the Safety Pillar through Isolation and Sandboxing. In an agentic IT environment, the agent is often writing and executing its own code. Relying on standard Docker containers, which share a host kernel, is no longer sufficient when dealing with autonomous, unvetted execution. The new pattern demands the use of “Agent Sandboxes“, donated by Google, a high-performance, ephemeral environments built on gVisor/Kata Containers. This allows the infrastructure to provide hardware-level isolation for every tool call an agent makes, ensuring that a “hallucinated” script or a rogue logic loop can never compromise the underlying node.
Parallel to safety is the need for Stateful Memory Fabrics. We are finally moving past the “stateless sin” of early AI, where every interaction required passing massive chat histories back and forth across the network. The infrastructure must now provide a tiered “Cognitive Memory” layer. Projects like the Model Context Protocol (MCP) are the first step here. But a stateful memory fabric isn’t just a or one database; it’s a fabric that moves from hot, local KV-caches for active reasoning to warm, shared memory for agent swarms, and finally to cold, vector-native storage. Maybe that even needs to be integrated directly into the Kubernetes storage class. By moving memory into the infrastructure, we allow agents to maintain context across restarts without the overhead of massive context-window bloat.
The third pillar is the radical reimagining of Dynamic GPU Scheduling. We are entering the age of “Bursty Reasoning.” Unlike a web server that sees steady traffic, an agent might sit idle for minutes while waiting for an external API, then suddenly require a massive burst of compute to plan its next ten moves. Static GPU reservation is an economic disaster in this model. We need a shift toward fractional vGPU scheduling and spatial multitasking, where the Kubernetes scheduler can slice and reallocate compute power in real-time based on the immediate “importance” of an agent’s reasoning task.
Finally, we must redefine Observability as Trust. In the microservices era, an HTTP 200 status code meant success. In the agentic era, an agent can return a success code while having completely failed its mission. We need to move beyond system logs and into “Reasoning Traces.” By extending protocols like OpenTelemetry, the infrastructure needs to capture the “Chain of Thought” alongside the code execution, allowing SREs to monitor the decision-making integrity and the cost-per-goal of an autonomous workforce.
From GitOps to AgentOps: The New Kernel
This all leads to the question: do we need to transition from GitOps to AgentOps? If Kubernetes is the kernel of the agentic operating system, we need a new way to interact with it. We are moving away from static manifests toward the Agentic CRD (Custom Resource Definition).
An Agentic CRD doesn’t just define an image and a port; it defines a goal, a budget, and a set of tool permissions. It allows the infrastructure to act as a governor rather than a micromanager. This requires a fundamental and perhaps uncomfortable shift in the engineering mindset. For the last decade, our mantra was: “It must run exactly the same on every machine.” In the agentic era, that shifts to: “It will somehow work on every machine.”
We are moving from Deterministic Reliability (the code always executes the same way) to Objective Reliability (the goal is reached, even if the agent takes a different path every time).
But we must ask ourselves: Do we actually want this?
By embracing this “somehow,” we gain immense power and speed, as seen in projects like Goose, which can autonomously fix its own dependencies. But we also surrender the comfort of the “frozen” production environment. If an agent uses MCP to pull live context and then spawns a unique Wasm sandbox to solve a problem, no two executions will ever look the same. We are trading the safety of the “known state” for the efficiency of autonomous reasoning.
The Path Forward
Because we are building faster models, more complex agent systems and diverse workloads, we have to build a more intelligent runtime. The road ahead requires us to unlearn much of what we know about “stable” infrastructure. We must embrace ephemerality, prioritize cognitive state, and build systems that can finally keep up with the unpredictability of autonomous thought.
Kubernetes has won the battle to be the platform. Now, it might be time to think about Kubernetes v2.
Further Resources:
- arXiv 2504.19413, “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory” (Apr 2025). Vector + graph hybrid; benchmarks show Mem0 graph construction completes in under a minute vs. Zep’s hours-long latency in worst case at arXiv.
- arXiv 2507.22925, “Hierarchical Memory for High-Efficiency Long-Term Reasoning in LLM Agents (H-MEM)” (Jul 2025). Multi-level abstraction with positional index encoding arXiv, a clean academic citation for tiered architectures.
- arXiv 2506.06326, “Memory OS of AI Agent” (MemoryOS) (Jun 2025). Three-tier STM/MTM/LPM with heat-based replacement arxiv, directly usable as a “hot/warm/cold” reference.
- arXiv 2604.07874, “Valve: Production Online-Offline Inference Colocation” (2026 preprint). Academic backing: production LLM inference is bursty in compute and KV-cache memory; SLA-driven peak provisioning leaves GPUs underutilized on average.
- Kubernetes upstream docs kubernetes.io/docs/concepts/scheduling-eviction/dynamic-resource-allocation/. Authoritative reference covering ResourceClaim, ResourceClaimTemplate, DeviceClass, Consumable Capacity (slicing 10 GiB out of a 40 GiB GPU), cloudkeeper Device Binding Conditions.
- llm-d project at llm-d.ai and github.com/llm-d/llm-d. Kubernetes-native distributed inference with vLLM, KV-cache-aware routing via Gateway API Inference Extension, Red Hat P/D disaggregation. Reported ~3× lower TTFT llm-d and ~2× throughput improvements with prefix-cache-aware routing on 8×H100 nodes.
- OpenTelemetry blog, “AI Agent Observability – Evolving Standards and Best Practices”-opentelemetry.io/blog/2025/ai-agent-observability/. OpenTelemetry now working on framework conventions for CrewAI, AutoGen, LangGraph, Semantic Kernel.
- OpenTelemetry, “OpenTelemetry for Generative AI”, opentelemetry.io/blog/2024/otel-generative-ai/. Original SIG announcement; defines gen_ai.* namespace.
- Langfuse, “AI Agent Observability, Tracing & Evaluation” langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse. Industry convergence on OTel.