
A deep dive into Kierra Dotson’s talk at MCP Dev Summit North America 2026
Almost all of MCP’s current adoption is happening in cloud environments, on large models with generous compute budgets. Manufacturing floors, medical devices, vehicles, smartphones,are where the next wave of AI deployments is headed.
Kierra Dotson, Director of AI Strategy at Further, wanted the MCP community to understand what it means to run a protocol designed for stable, high-bandwidth infrastructure on devices where a missed packet could mean a failed diagnosis or a defect clearing a production line.
The Three Assumptions MCP Makes That the Edge Breaks
MCP’s current design works well in the cloud because of three conditions it quietly assumes:
- High bandwidth
- Persistent Connectivity
- Cheap Compute
On a large cloud model with a 100,000-token context window, verbose JSON payloads are a minor inconvenience. On a small language model (Phi, Llama, Gemma) running on a constrained device with a 4–8K context window, they’re a structural problem. A standard MCP tool schema can consume the majority of an edge model’s available context before the first real prompt even arrives.
Kierra’s talk laid out three concrete proposals for adapting MCP to environments where those assumptions don’t hold. Each addresses a distinct failure mode, and together they form what she described as an edge-native MCP stack.
1. Binary MCP: Shrinking the Wire
The first proposal targets the wire format itself.
JSON-RPC is human-readable, which helps during development. But a production line edge device processing hundreds of tool calls per minute doesn’t need a human-readable payload. It needs to process the data fast.
Kierra’s proposal is to replace JSON on the wire with protocol buffers (protobuf), the binary serialization format Google developed for microservice communication. A typical MCP tool call in JSON runs 2–5 kilobytes. The same message encoded as protobuf compresses to around 200 bytes, a 10–25x reduction in payload size. Binary deserialization is also 10–50x faster than JSON parsing, because the structure is precompiled rather than scanned at runtime.
The practical benefit on a factory floor means smaller payloads mean faster round trips, lower CPU load, and less battery drain from the radio hardware transmitting. At high throughput, that compounds quickly.
Backward compatibility is preserved through a capability negotiation step during connection setup. If the server supports binary MCP, it selects it. If not, it falls back to JSON. The language model never sees any of the binary processes. From its perspective, it receives a structured tool result, same as always.
The key constraint: binary MCP pays off when host and server are on separate physical devices connected by a constrained link (Bluetooth LE, ZigBee, congested Wi-Fi, cellular). On the same machine over a Unix socket, the overhead difference is negligible.
2. Resilient Transport and Session Continuity
The second problem is that smaller messages still fail completely if the network drops.
SSE requires a persistent HTTP connection. A single network blip forces the client to restart from scratch, re-establishing session state entirely. On a cloud deployment with load balancing, this is rare. On an edge device with aggressive power management and intermittent connectivity, it’s a fundamental mismatch between protocol assumptions and deployment reality.
Kierra’s proposal substitutes MQTT (a lightweight messaging protocol designed for high-latency, unreliable networks) combined with a local persistence layer.
In her factory floor scenario, the defect detection model needs to flag a suspected defect and log it to the central quality system. At that exact moment, the device’s Wi-Fi drops for 500 milliseconds. Under current MCP with SSE, the tool call fails. The session state is lost. The defect goes unlogged.
With store-and-forward, the MCP client writes the tool call to local storage (a SQLite outbox) before it even touches the network. The call is now durable:
- It survives application crashes, battery death, and process kills.
- When connectivity restores, the MQTT client publishes the pending call to the broker, which delivers it to the MCP server.
- If the client is still offline when the result arrives, it receives the result the moment it reconnects.
No polling, no re-requesting, no repeated work.
Paired with this is session continuity. Today, MCP sessions are stateless by default, and a reconnecting client starts over. Kierra proposes adding a session ID and sequence number to the MCP message header, so a server can replay missed notifications when a client reconnects with a known session ID. A defect detection model mid-way through a multi-turn analysis can sleep, wake 20 minutes later, and pick up its reasoning chain without restarting.
The tradeoff is architectural complexity. That cost is worth it when calls must not be lost, safety flags, audit events, diagnostic logs. For local development or a reliable cloud deployment, SSE remains the right choice.
3. Semantic Tool Compression and Content-Addressable Context
The third proposal actually bundles two related problems.
The first is tool schema verbosity. When a model requests the tools list from an MCP server, it gets a full JSON payload for every tool the server exposes: parameters, types, descriptions. For a small language model doing one task on a factory floor, 42 of those 50 tools are irrelevant. Returning them wastes context and increases the probability of tool hallucination, because the model is reasoning over a larger option space than it needs.
Kierra’s solution is to let clients pass session context when requesting tools. A model currently running a quality inspection task on an automotive body requests only tools relevant to defect detection. The server returns 8 tools instead of 50. The attack surface shrinks as a side effect, a tool not in the schema can’t be called, can’t be hallucinated, and can’t be injected through a malicious prompt.
The second problem is redundant sensor polling. A system monitoring coolant temperature, conveyor belt speed, and machine vibration reads those sensors on a loop, but those values are stable for minutes or hours at a time. Under current MCP, every resource request returns a full payload regardless of whether anything changed.
Kierra proposes content-addressable context: before sending a resource payload, the server sends a hash. The client checks the hash against its local cache. If they match, it skips the download entirely. If the hash is new, it requests the full payload and caches the new hash. For a fleet of edge devices pulling dozens of sensors hundreds of times per minute, that’s a substantial reduction in network and CPU load, the same principle as HTTP ETags, baked into the MCP layer as a first-class feature.
Local-First Resource Discovery
A short but pointed final section addressed a problem specific to high-volume data sources like video.
Kierra described watching a demo of an MCP server for video intelligence where footage travels to cloud infrastructure, gets indexed, and returns results. That architecture doesn’t work on a production line that needs a decision in milliseconds. By the time footage leaves the building and the result comes back, the defective unit has already cleared the rejection point.
Her proposal is a local-first resource discovery scheme using a specialized URI (mcp-local://), with a strict separation between what MCP is responsible for and what it isn’t. The MCP server is the analysis and decision layer. It is not a data transportation layer.
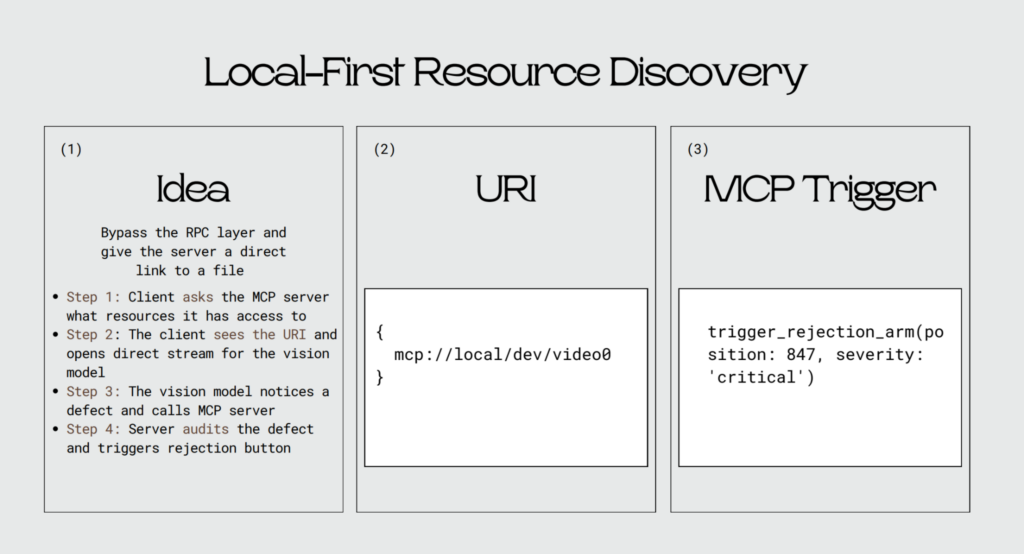
In practice, the vision model receives raw video frames directly from the camera, no encoding, no envelope. When it detects a defect, it calls the MCP server with a structured finding. The server never sees a raw frame. It sees a result, evaluates it, and triggers the rejection arm via a binary MCP tool call. The arm fires. The unit diverts. The event is logged. The raw stream and the intelligence layer never share the same path.
Why This Matters Now
Kierra closed with a clear-eyed read of where this is heading: the edge isn’t going to wait for consensus. With billions of dollars already flowing into edge AI infrastructure, she expects binary MCP forks to emerge in the wild within two to three years, whether or not the core specification catches up.

Her argument isn’t that MCP needs to be replaced. Binary MCP is backward-compatible. The caching layer is opt-in. Local-first resource discovery is a URI scheme. Existing cloud deployments continue working as-is. But edge deployments need these optimizations, and the MCP community is well-positioned to build them rather than watch the ecosystem fragment.
Kierra Dotson is Director of AI Strategy at Further. The Agentic AI Foundation is the home of open agentic standards and open source infrastructure. To learn more about MCP and connect with engineers thinking through these problems, visit aaif.io, join the conversation in the AAIF Discord, or join us at an upcoming AAIF event.